Frequently Asked Questions
First, here are a few key properties about Glaze that might help users understand how it works.- Image specific: The cloaks needed to prevent AI from stealing the style are different for each image. Our cloaking tool, run locally on your computer, will "calculate" the cloak needed given the original image and the target style (e.g. Van Gogh) you specify.
- Effective against different AI models: Once you add a cloak to an image, the same cloak can prevent different AI models (e.g., Midjourney, Stable Diffusion, etc.) from stealing the style of the cloaked image. This is the property known as transferability. While it is difficult to predict performance on new or proprietary models, we have tested and validated the performance of our protection against multiple AI models.
- Robust against removal: These cloaks cannot be easily removed from the artwork (e.g., sharpening, blurring, denoising, downsampling, stripping of metadata, etc.).
- Stronger cloak leads to stronger protection: We can control how much the cloak modifies the original artwork, from introducing completely imperceptible changes to making slightly more visible modifications. Larger modifications provide stronger protection against AI's ability to steal the style.
Basic hints if you're having problems:
- If you are running Glaze app on a mac, please make sure you have the right version (Intel mac vs M1/M2/M3 Mac). Please make sure you are running MacOS 13.0 or later.
- If WebGlaze is not responding to your uploaded image, please make sure you do not have any international characters in the filename
- Glaze/WebGlaze only runs on JPG or PNG files, other formats will produce errors.
- For best results, send Glaze/WebGlaze PNG files, then you can convert the Glazed PNG file and compress it as much as you would like.
- If running the Glaze app is getting a missing .json file error, look in the directory mentioned in the error message. IF there is a zip file, unzip it. Sometimes the installer fails to unzip all files, and unzipping will fix the problem. Then try running the app again.
- If you are running NVidia GTX 1660/1650/1550 GPUs, PyTorch has a long known bug with those GPUs, and Glaze uses PyTorch. Unfortunately Glaze will not run correctly on those GPUs. We recommend WebGlaze instead.
How could this possibly work against AI? Isn't AI
supposed to be smart?
This is a popular reaction to cloaking, and quite
reasonable. We hear often in the popular press how
amazingly powerful AI models are and the impressive
things they can do with large datasets. Yet the
Achilles' heel for AI models has been its inability to approximate
what humans see. This is most clearly demonstrated in a phenomenon
called adversarial examples-- small tweaks in inputs
that can produce massive differences in how AI models
classify the input. Adversarial examples have been
recognized since 2014 (here's one
of the first papers
on the topic), and numerous papers have attempted to
prevent these adversarial examples since. It turns out
it’s extremely difficult to remove the possibility of
adversarial examples from being used in training
datasets, and in a way are a fundamental consequence of
the imperfect training of AIs. Numerous PhD
dissertations have been written this subject, but suffice it to
say, the gap between human and AI 'perception' remains a
fundamentally part of machine learning algorithms.
The underlying techniques used by our cloaking tool draw directly from the same properties that give rise to adversarial examples. Is it possible that AI models evolve significantly to eliminate this property? It's certainly possible, but we expect that would require significant changes in the underlying architecture of AI models. Until then, cloaking works precisely because of fundamental weaknesses in how AI models are designed today.
Can't you just take a screenshot of the artwork to destroy the image cloaks?
The cloaks make calculated changes to pixels within the images. The changes vary for each image, and while they are not necessarily noticeable to the human eye, they significantly distort the image for AI models during the training process. A screenshot of any of these images would retain the underlying alterations, and the AI model would still be unable to recognize the artist’s style in the same way humans do.
Can't you just apply some filter, compression, blurring, or add some noise to the image to destroy image cloaks?
As counterintuitive as this may be, the high level answer is that no simple
tools work to destroy the perturbation of these image cloaks. To make sense
of this, it helps to first understand that cloaking does not use
high-intensity pixels, or rely on bright patterns to distort the image. It is
a precisely computed combination of a number of pixels that do not easily
stand out to the human eye, but can produce distortion in the AI's “eye.” In
our work, we have performed extensive tests showing how robust cloaking is to
things like image compression and distortion/noise/masking injection.
Another way to think about this is that the cloak is not some brittle watermark that is either seen or not seen. It is a transformation of the image in a dimension that humans do not perceive, but very much in the dimensions that the deep learning model perceive these images. So transformations that rotate, blur, change resolution, crop, etc, do not affect the cloak, just like the same way those operations would not change your perception of what makes a Van Gogh painting "Van Gogh."
Isn't it true that Glaze has already been broken/bypassed?
No, it has not. Since our initial release of Glaze on March 15, 2023, a number
of folks have attempted to break or bypass Glaze. Some attempts were more
serious than others. Many detractors did not understand what the mimicry
attack was, and instead performed Img2Img transformations on Glazed art (see
below). Other, more legitimate attempts to bypass Glaze include a PEZ reverse
prompt attack by David Marx, the results of which he posted
publicly. Others thought that removing artifacts produced by Glaze was
equivalent to bypassing Glaze, and developed pixel-smoothing tools, including
AdverseCleaner by Lyumin Zhang, author of ControlNet. A few days after
creating the project, he added a note on March 28, 2023 admitting it doesn't
work as planned.
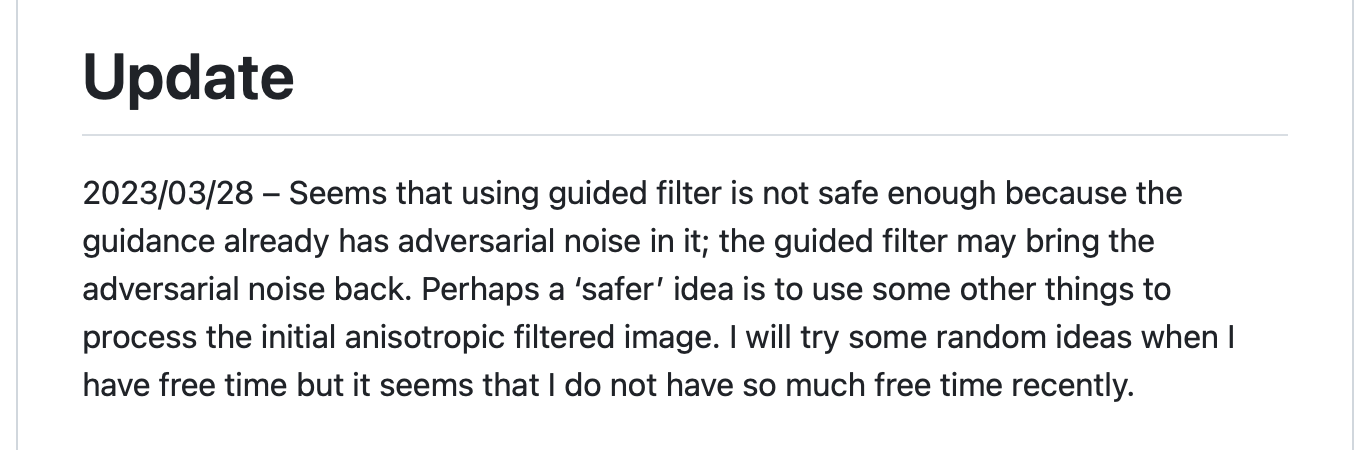
For folks interested in detailed test results showing the impact of these attempts to bypass Glaze, please take a look at the official Glaze paper here.
Does Glaze protect against Image2Image transformations?
Glaze was designed to protect artists against art style mimicry, not img2img
attacks. Since then, we have seen evidence to suggest that Glaze as a tool
can potentially disrupt img2img attacks at very high intensity levels. From
our limited tests, we observe that Glaze provides some protection against
weaker img2img style transfers, such as built in functions in Stable
Diffusion, but that protection against stronger img2img tools like controlnet
require much higher intensity settings. At this time, we do not believe Glaze
provides consistent protection against img2img attacks, including style
transfer and inpainting.
The only tool we are aware that claims strong disruption of img2img attacks is Mist. Mist is an open source tool created by several PhD students in the US and China. Our initial analysis of Mist is that its internal approach/implementation is very similar to Glaze, and its strong anti-img2img properties come from its high intensity settings, which are more than 5x what Glaze considers its highest intensity setting. We expect those to be unacceptable for most artists. Meanwhile, we continue tests to understand / explore Glaze's potential disruption against img2img. Stay tuned.
Will there be a version for my Android/iOS tablet or phone? A Glaze web
service?
There will not be a mobile Android/iOS version, but yes, we have WebGlaze!
WebGlaze is a free-to-artists web service that runs Glaze on GPU servers
in the Amazon cloud. It is paid by the SAND Lab, and access to WebGlaze is
free for human artists who do not use AI. Any human artist can request an
account invite for free, just by sending us a direct message on Twitter or
Instagram (@TheGlazeProject on both). Once you create an account, you can
log in to WebGlaze, upload
an art image, enter your email, select intensity, and hit go. WebGlaze
runs glaze on the image, emails you the result, and then deletes all
images immediately thereafter. WebGlaze will remain invite-only to human
(non-AI) artists, because it does cost $ for us to run.
You can read more about WebGlaze here. Currently, WebGlaze has an advantage over the Glaze app in that it handles image metadata a bit better. By default, it runs on a setting equivalent to the Glaze app's max render quality.
How can I help support Glaze?
Thank you so much for thinking of us. It is important to us that we not only continue to provide Glaze to visual
creators for free, but also extend its protective capabilities. If you or your organization may be interested in
pitching in to support and advance our work, you can donate directly to Glaze via the Physical Sciences Division webpage, click on "Make
a gift to PSD" and then choose "GLAZE" as your area of support in the dropdown box (managed by the University of Chicago Physical
Sciences Division).
If you are looking to volunteer for the Glaze project, you can email Ben (ravenben at uchicago dot edu)
directly. It is challenging for us to work with remote volunteers, but you can reach out regardless.
How can glazing be useful when I have so many original artworks
online that I can't easily take down?
Glazing works by shifting the AI model's view of your style in its “feature
space” (the conceptual space where AI models interpret artistic styles). If
you, like other artists, already have a significant amount of artwork online,
then an AI model like Stable Diffusion has likely already downloaded those
images, and used them to learn your style as a location in its feature
space. However, these AI models are always adding more training data in order
to improve their accuracy and keep up with changes in artistic trend looks
over time. The more cloaked images you post online, the more your style will
shift in the AI model's feature space, shifting closer to the target style
(e.g., abstract cubism). At some point, when the shift is significant
enough, the AI model will start to generate images in van Gogh's style when
being asked for your style.
We found that as long as there is even a slight shift in the AI model's feature space, the AI model will create images that is noticeably different from your style. For example, the generated images may resemble an (uncomfortably creepy) hybrid of your style and abstract cubism blended in.